This guide includes general developer documentation for DINA modules. Topics that are more related to the DINA system as a whole are covered in local-deployment documentation. Documentation about modules implementation is in dina-base-api
UI development documentation (including the UI design guidelines) is covered in the dina-ui documentation.
1. API Specifications
| API | Specification | Implementation |
|---|---|---|
Collection API |
||
Object Store API |
||
Agent API |
||
Sequence API |
||
Export API |
||
Search API |
2. High Level Architecture
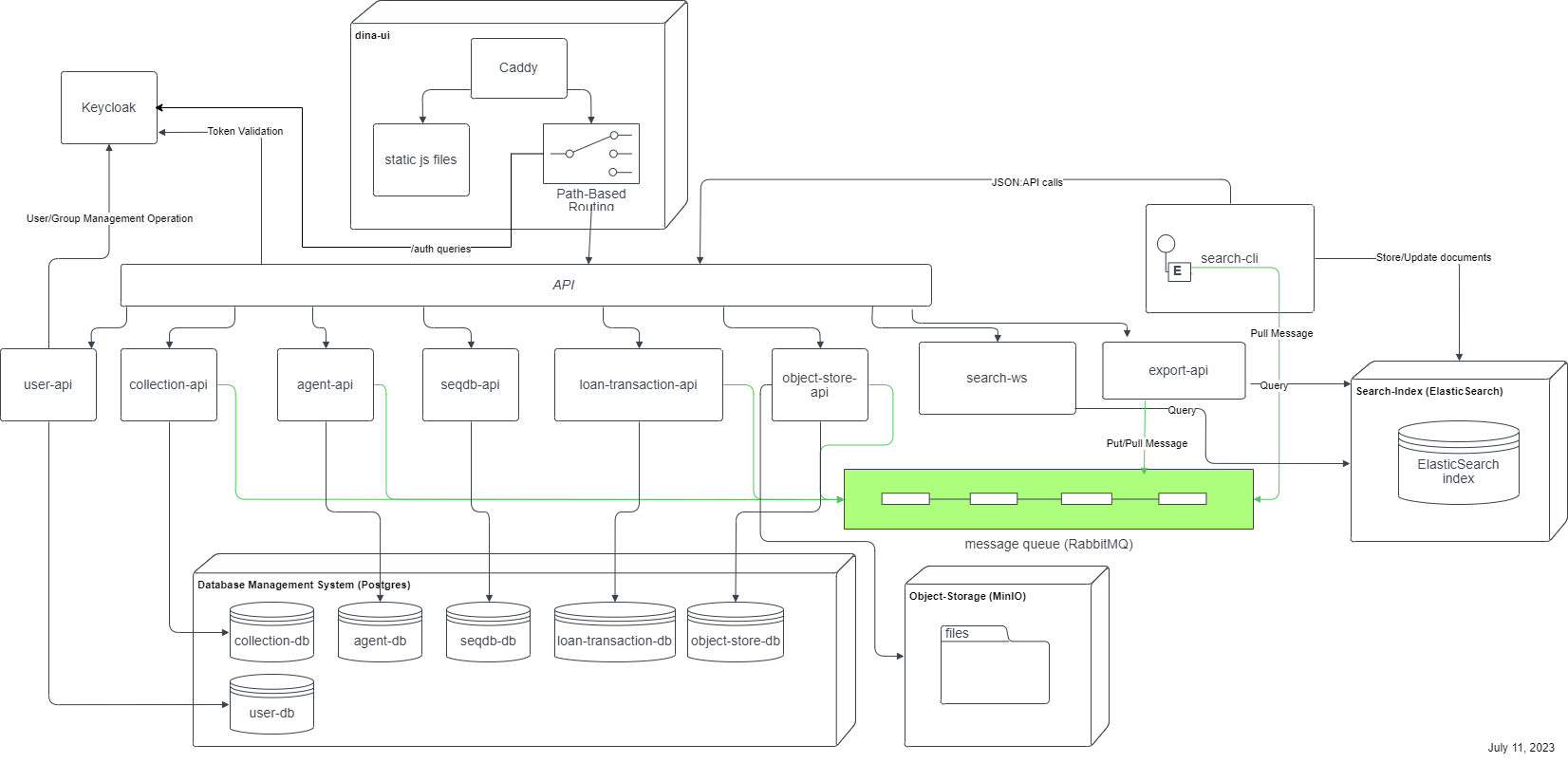
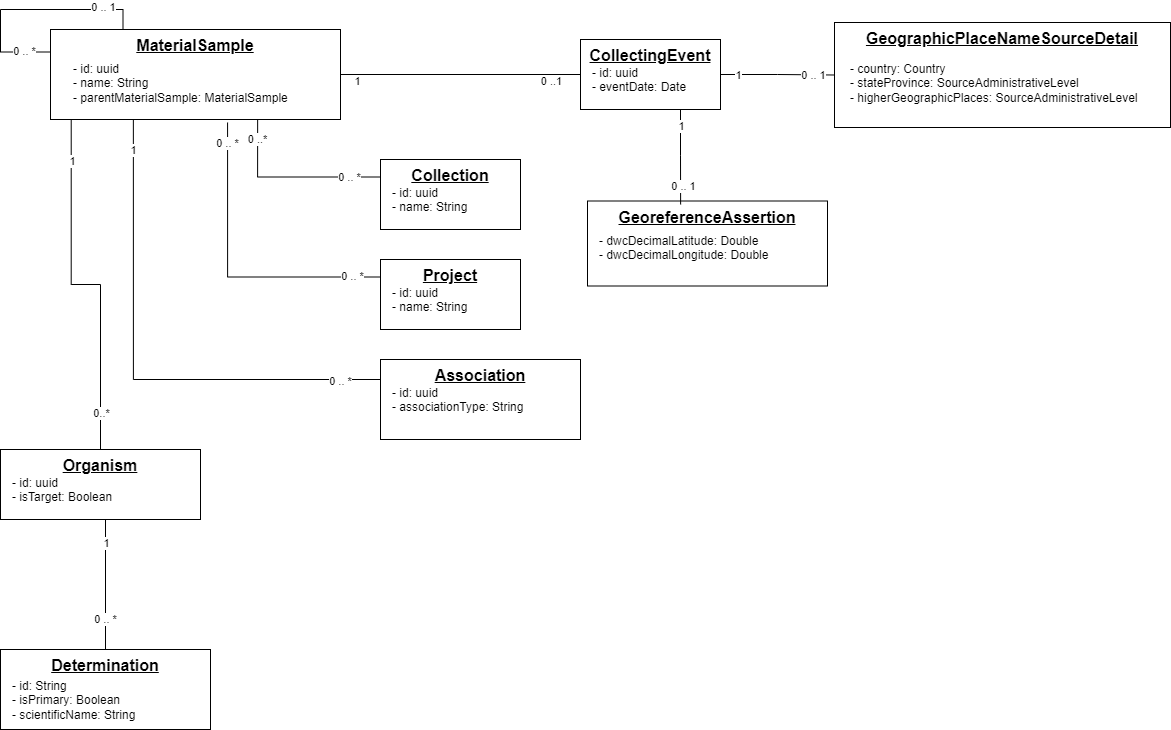
3. High Level Design
4. IDE Setup
DINA Java-based projects are using Lombok, which may require additional setup in your IDE: IDE setup guides.
5. Keycloak
5.1. Groups
Groups are used to represent ownership access. A user can be in groups like group-1, group-2, etc, which would let them access certain collections and data sets but not others.
This could be done by checking the metadata of the particular item the user is trying to access against their group membership. New groups could be added without having to recompile or edit the configuration
of the deployment.
| If you are planning to use the object-store, make sure the group names are following s3 bucket naming rules |
5.2. Roles per group
Roles per group are not directly supported by Keycloak. Groups are mostly used to assign a set of Roles to users inside a group. For example, a user with the role "Super User" could be in 2 groups group-1 and group-2
but we would have no way to restrict to role to a certain group so the user would be a "Super User" in both groups. Creating very specific roles like “Group 1 Super User” is not really an option since it
would make the implementation quite complex in all the modules.
Since Keycloak supports subgroups, we can have subgroups like /group-1/super-user (subgroup of group-1) and use that to determine access in group-specific situations. It breaks away somewhat from the conceptual
separation of using roles for functional access and groups for ownership, but it still represents a functional solution that mixes both concepts.
Groups, including subgroups, can also have role mappings, which assign a specified role to all members of a group. As an example, a group-admin role which would be role-mapped to each of the …/admins groups.
That would let us use the native role-based features of Spring Security as an initial check, then verify in code that the user belongs to the correct admin subgroup for whatever they’re trying to do.
5.3. User Attributes
User attributes can be set using the Keycloak console. They will be returned in the Keycloak token so the services and user interface can use it.
agentId: UUID of the person in the agent module to allow all the modules to be aware of the agent identifier that represents the authenticated users.
5.4. Group Attributes
Group attributes can be set using the Keycloak console. They will be returned by the user module.
groupLabel-en: label to display the group label by language (specified in the suffix with 2 letters ISO code)
6. DINA APIs
DINA modules provide a REST API that conforms to the JSON:API specification. DINA Web API Guidelines provides a more specific context and includes some design decisions.
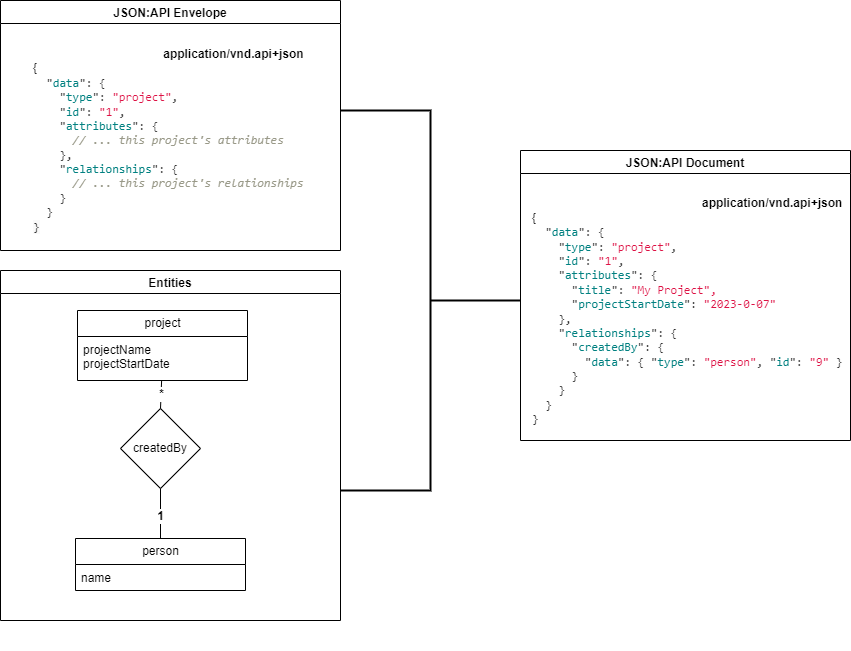
6.1. Sparse field selection
You can limit which fields are included in a response using the fields.
Listing regions with "name" and "description" as the only included fields:
/api/region?fields[region]=name,description
6.2. Optional field inclusion
Some endpoints can have fields that are expensive to compute/query that are not included by default. Since they are not relationships they can’t be included using the include parameters.
The optfields[type] parameter can be used.
GET /api/region?optfields[region]=hierarchy
6.3. Filtering
6.3.1. Simple Filters
While JSON:API does not suggest a formal resource filtering mechanism, DINA is using a simple form of filtering based on filter, operator and value.
GET /person?filter[firstName][EQ]=John&filter[lastName][EQ]=Doe
Get the persons where the firstName is John OR Jane
GET /person?filter[firstName][EQ]=John,Jane
Get the persons where the lastName is null
GET /person?filter[lastName][EQ]=null
Example of returning all derivitives of the metadata with UUID 44b62cbc-5e7f-4e68-86d2-2819e3f5e9e7:
GET /metadata?filter[acDerivedFrom.id][EQ]=44b62cbc-5e7f-4e68-86d2-2819e3f5e9e7
Supported operators:
-
EQ
-
NEQ
-
IN (comma-separated list of values, if the value has a comma, the value can be quoted)
-
LIKE ('%' as a wildcard for zero or more characters)
-
GT (for numbers and dates)
-
GOE (for numbers and dates)
-
LT (for numbers and dates)
-
LOE (for numbers and dates)
Implementation details can be found on dina-base documentation.
6.3.2. FIQL
The Feed Item Query Language is a simple but flexible, URI-friendly syntax for expressing filters across the entries in a Web feed. Examples and details can be found on Apache CXF JAX-RS Search.
localhost:8080/api/region?fiql=name==12S,name==142
6.3.3. RSQL
| Deprecated. Replaced by FIQL. |
DINA supports RSQL (REST query language) for more complex filter queries.
localhost:8080/api/region?filter[rsql]=( name=='12S' or name=='142' )
returns
{
"data": [
{
"id": "142",
"type": "region",
"attributes": {
"symbol": "142",
"name": "142",
"description": ""
}
},
{
"id": "284",
"type": "region",
"attributes": {
"symbol": "12S",
"name": "12S",
"description": "mitochondrial"
}
},
{
"id": "366",
"type": "region",
"attributes": {
"symbol": "12S",
"name": "12S",
"description": null
}
}
]
}
6.4. Pagination
You can paginate list data using "page[limit]" and "page[offset]" parameters.
The first page of regions with a page size of 100:
/api/region?page[limit]=100
The second page:
/api/region?page[limit]=100&page[offset]=100
6.5. Sorting
You can sort listed data in ascending or descending order, and specify multiple sort fields.
Sorting regions by name (ascending):
/api/region?sort=name
Sorting regions by name (descending):
/api/region?sort=-name
Sorting regions by name (ascending) and description (descending when multiple regions have the same name):
/api/region?sort=name,-description
6.6. Creating a resource
Creating a new Region:
curl -XPOST -H "Content-Type: application/vnd.api+json" \
--data '{"data":{"type": "region", "attributes": {"name":"My Region", "description":"My Description", "symbol":"My Symbol"}}}' \
http://localhost:8080/api/region6.7. Bulk operations
Since bulk operations are not officially in JSON:API the Content-Type application/vnd.api+json; ext=bulk is used.
6.7.1. Create and Update Bulk Operations
POST and PATCH accept a list of resource objects under the attribute data. It is done on the (resource-endpoint)/bulk endpoint.
Example request:
HTTP Method: POST (or PATCH)
URL: agent-api/person/bulk
Headers:
-
Content-Type:
application/vnd.api+json; ext=bulk -
Accept:
application/vnd.api+json
Body:
{
"data": [
{
"type": "person",
"attributes": {
"displayName": "John Doe"
},
"relationships": {
"organizations": {
"data": [
{
"id": "711e5e9c-18c5-4994-92db-8723535b9f1f",
"type": "organization"
}
]
}
}
},
{
"type": "person",
"attributes": {
"displayName": "Jane Doe"
}
}
]
}6.7.2. Delete Bulk Operation
DELETE accepts a list of resource identifier objects under the attribute data. It is done on the (resource-endpoint)/bulk endpoint.
Example request:
HTTP Method: DELETE
URL: agent-api/person/bulk
Headers:
-
Content-Type:
application/vnd.api+json; ext=bulk -
Accept:
application/vnd.api+json
Body:
{
"data": [
{
"type": "person",
"id": "fd9e3638-c017-4643-8769-6ef6d0f9234f"
},
{
"type": "person",
"id": "64827579-6063-4204-9fdf-ce1edbc8c627"
}
]
}6.7.3. GET Bulk Operation
GET is a special case due to the fact that it can’t officially have a body. We are then using POST on (resource-endpoint)/bulk-load endpoints that are configured on
each supported resources. They accept a list of resource identifier objects under the attribute data.
An optional url param called include can be used to retrieve relationships within the same API module. To use it, a comma separated list can be provided with the relationship names to include.
Example request:
HTTP Method: POST
URL: agent-api/person/bulk-load
URL Params:
-
include:
identifiers,organizations(optional), relationship names to be included with the query.
Headers:
-
Content-Type:
application/vnd.api+json; ext=bulk -
Accept:
application/vnd.api+json
Body:
{
"data": [
{
"type": "person",
"id": "fd9e3638-c017-4643-8769-6ef6d0f9234f"
},
{
"type": "person",
"id": "64827579-6063-4204-9fdf-ce1edbc8c627"
}
]
}7. Logging
Hibernate
logging.level.org.hibernate.SQL: DEBUG
logging.level.org.hibernate.type.descriptor.sql.BasicBinder: TRACEDINA
logging.level.ca.gc.aafc.dina: DEBUG8. Controlled Vocabulary
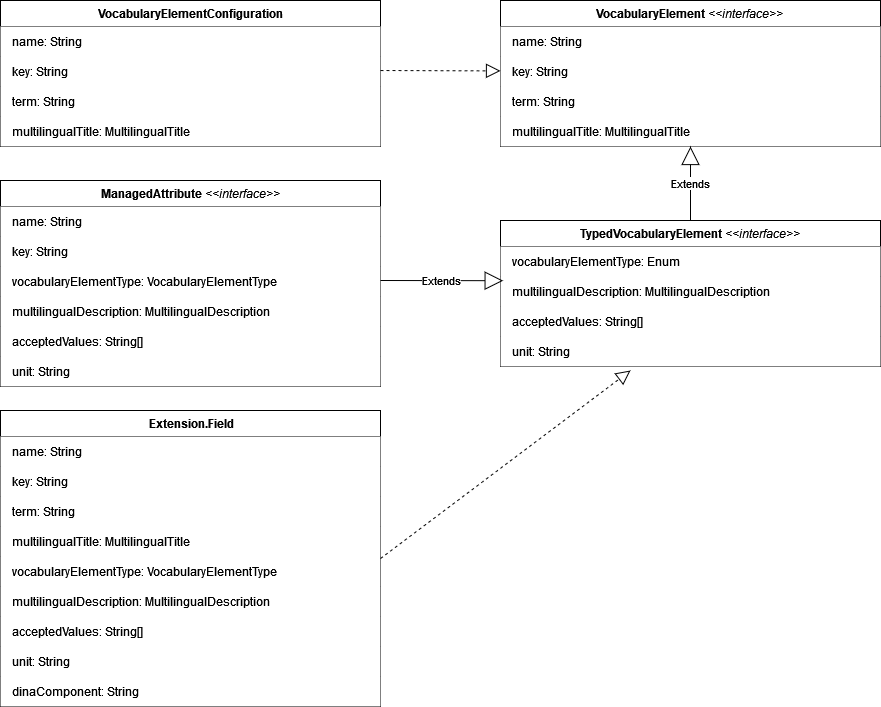
8.1. Controlled Term
Represents a single thing/concept with no separate literal value. Used to either suggest or restrict values for some fields defined in the DINA models.
Examples: spatial reference system (SRS), type status, coordinate system …
8.2. Qualified Value
Represents a single thing/concept with a typed literal. Used to store additional information that is not structly defined in the DINA models.
Examples: pH: 7.2, grainSize: 2.7 mm
8.3. Managed Attribute
A managed attribute is a predefined instance of Qualified Value where the user can add new entries.
Used as semi-structured data where the key is stored with a value on the DINA models that support them.
8.4. Field Extension
Field extension represents a set a terms/concepts that are logicialy grouped. They usualy comes from a standard defined by an external body.
They are used as semi-structured data where the extension, the version and the key are stored with a value on the DINA models that support them.
9. Liquibase
Liquibase is used to generate the database and migrate to new versions of the database schema. Changelogs are source xml files that describe schema changes to the database. Liquibase maintains a "DATABASECHANGELOG" table in the same database to keep track of which changelogs have been executed. When the application starts, any changelogs that have not been executed are executed.
Additional information:
9.1. Liquibase Contexts
When developing for Dina modules certain data is needed for the application to run properly and to make testing easier. Which is why we separate our database migrations into categories known as contexts. The two main contexts are as follows:
-
schema-change
-
Changes to the schema such as adding new columns, renaming tables, adding new tables.
-
-
sample-data
-
sample data for developers, this should not be ran on PROD/UAT since it’s used for inserting sample data for developers and the data is already in PROD/UAT databases.
-
For PROD/UAT purposes, the context can be changed by editing the application.yml file which has all of the liquibase configurations. The contexts are a comma separated list of all of the contexts to be performed.
9.2. Liquibase migration file convention
The following convention should be followed by all Liquibase database migration files:
-
Migration scripts live in
src/main/resources/db/changelog -
Filename should follow the convention
<UNIQUE_INCREMENTAL_ID>-<ISSUE_TITLE>.xml(e.g.2-new_specimen_field_PHAC_containment_level.xml) -
A new migration file’s path should be added in an "include" tag of
src/main/resources/db/changelog/db.changelog-master.xml -
The context of a
changeSetin the migration xml file should always be set (e.g.context="schema-change") -
The
<id>should use the filename convention without the file extension<UNIQUE_INCREMENTAL_ID>-<ISSUE_TITLE>if the file only includes 1 changeset, otherwise the following convention should be used:<UNIQUE_INCREMENTAL_ID>-<ISSUE_TITLE>-<WHAT_THE_CHANGESET_DOES>(ex:id="11-Implement_new_workflow_entitie-Create_enum_types")
When merging code to dev, we need to make sure the incremental number is always unique. If we have a duplicate, we should be reassigned a new identifier and update the db.changelog-master.xml.
10. Releasing a DINA module
The process of releasing a dina module is the same for all modules. The CI will automatically build and release a new Docker image to Docker Hub when something is merged in the master/main branch.
BICoE Docker Hub: https://hub.docker.com/u/aafcbicoe
Java-based API:
-
From dev branch
-
Change the version by running
mvn versions:set -DnewVersion=X.Xfrom the root whereX.Xis the current version minus the-SNAPSHOT -
Add and Push to dev with message like "Prepare version x.x release"
-
Wait for CI to complete
-
-
From master/main
-
Merge dev into master (do NOT use Pull Request)
-
Push to master (it will trigger the deployment Docker Hub)
-
-
Create a new GitHub release
-
The tag should be the version prefixed with v (e.g. v0.19)
-
The title should be the version (e.g. 0.19)
-
Add a Summary of the changes (looks at the previous versions for an example)
-
Publish the Release
-
-
From dev branch
-
Change the version by running
mvn versions:set -DnewVersion=X.X-SNAPSHOTfrom the root where X.X is the next increment in the version number -
Add and Push to dev with message like "Prepare next development version"
-
DINA-UI:
-
From dev branch
-
Edit the the file
packages/dina-ui/package.jsonand set theversionvalue
-
Same as the Java-based API except the second From dev branch can be skipped since the ui is not using development version.
11. PostgreSQL
11.1. Useful Queries
11.1.1. Rename key in jsonb array
The example is not aiming at perfomance.
Considering the following table :
CREATE TABLE organism (id integer, determinations jsonb);With jsonb array in the determinations column:
INSERT INTO organism VALUES (1, '[
{
"scientificNameSource": "GNA",
"isPrimary": true,
"isFileAs": true
},
{
"scientificNameSource": "GNA",
"isPrimary": false,
"isFileAs": false
}
]');We want to rename the key isFileAs to isFiledAs:
-- unwrap the array and extract the value
WITH subquery AS (
SELECT id, item, item -> 'isFileAs' as att_value
FROM organism, jsonb_array_elements(determinations) as item
),
-- remove the old attribute and create the new one with the value
-- reconstruct the array by grouping by id
subquery2 AS (
select id, json_agg(jsonb_set(item-'isFileAs', '{isFiledAs}', att_value)) as updated_jsonb from subquery
GROUP BY id
)
UPDATE organism
SET determinations = updated_jsonb
FROM subquery2
WHERE organism.id = subquery2.id;12. Elasticsearch
To add a new field to the mapping see DINA deployment documentation.
12.1. Update Mapping
When a new mapping or new mapping property must be added to a live index the Update mapping API can be used.
If the new mapping requires new Analyzer, an update settings analysis is required first.
Example:
Assuming keyword_lowercase_analyzer is already declared, add it to the multi-field data.attributes.originalFilename:
curl -X PUT "localhost:9200/dina_object_store_index/_mapping?pretty" -H 'Content-Type: application/json' -d'
{
"properties": {
"data.attributes.originalFilename": {
"type": "text",
"fields": {
"prefix": {
"type": "text",
"analyzer": "keyword_lowercase_analyzer",
"index_prefixes": {
"min_chars" : 1,
"max_chars" : 10
}
},
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
'
Refesh the index:
curl -X POST "localhost:9200/dina_object_store_index/_update_by_query?refresh"
12.2. Delete Included Field with Update By Query
To remove a specific field from a nested object within your Elasticsearch documents, you can use an update_by_query request:
POST 127.0.0.1:9200/dina_material_sample_index/_update_by_query
{
"script": "for (int i = 0; i < ctx._source.included.length; ++i) { ctx._source.included[i].attributes.remove(\"ATTRIBUTE_NAME\") }",
"query": {
"nested": {
"path": "included",
"query": {
"bool": {
"must": [
{
"exists": {
"field": "included.attributes.ATTRIBUTE_NAME"
}
}
]
}
}
}
}
}
Replace ATTRIBUTE_NAME with the field you wish to remove. And also change the index in the URL if needed. Then you can re-run the elastic-configurator.
In the elastic-configurator, you should see the following for the index you have updated if it worked correctly:
Running update script for optional mapping The update request was successful Re-indexing documents. Source index is: dina_material_sample_index_20241112154013 and destination index is: dina_material_sample_index_20241112193452 Response is: 200 Old index doc count: 2 New index doc count: 2 Document counts match. Proceeding with deletion of old index and setting alias... Updating index dina_material_sample_index_20241112193452 with alias dina_material_sample_index
Then, re-index the affected documents so the data is restored in the new format based on the migration.